NVIDIA Inference Microservices(NIM)
NVIDIA Inference Microservices(NIM)
There are 170+ of models by NVIDIA. You can find them here: NVIDIA Models
Key Features of NVIDIA Inference Microservices
- Production-Ready Deployment
- Pre-configured containers with optimized runtime environments
- Automated scaling and load balancing
- Built-in monitoring and logging capabilities
- Enterprise-grade security features
- Hardware Optimization
- Specifically tuned for NVIDIA GPUs
- Supports multiple GPU architectures (Ampere, Hopper, Ada Lovelace)
- Efficient resource utilization
- Dynamic batch processing
This blog explains using two NIM models by Nvidia:
-
meta/llama3-70b-instruct, and
-
nvidia/nv-embedqa-e5-v5
meta/llama3-70b-instruct
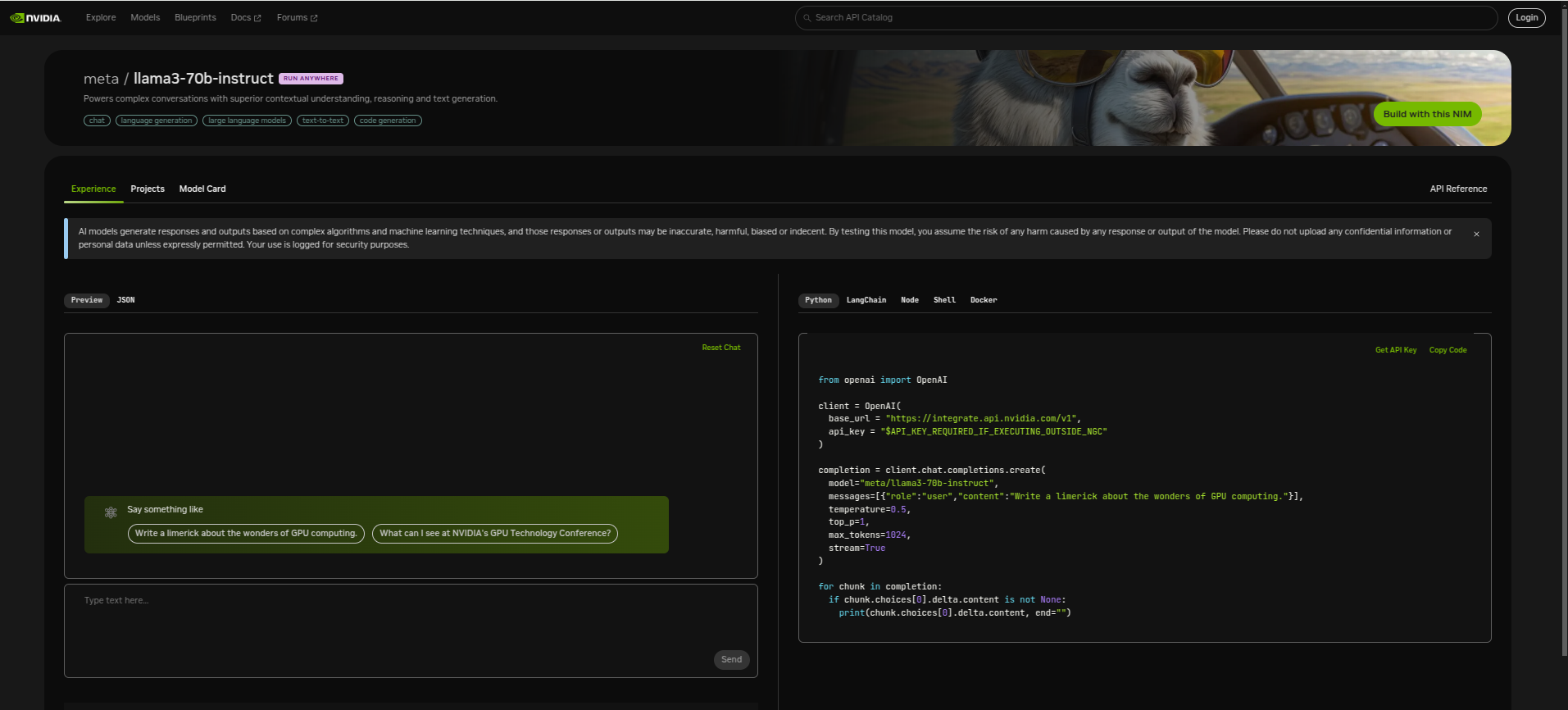
This model is a large language model developed by Meta. The model is designed to be a general-purpose language model that can be used for a wide range of natural language processing tasks, including language translation, text generation, and question answering.
The model is available on the Hugging Face platform and can be used with the Hugging Face Transformers library. It is also available on the NVIDIA Inference Microservices platform, which provides a cloud-based infrastructure for running inference on NVIDIA GPUs.
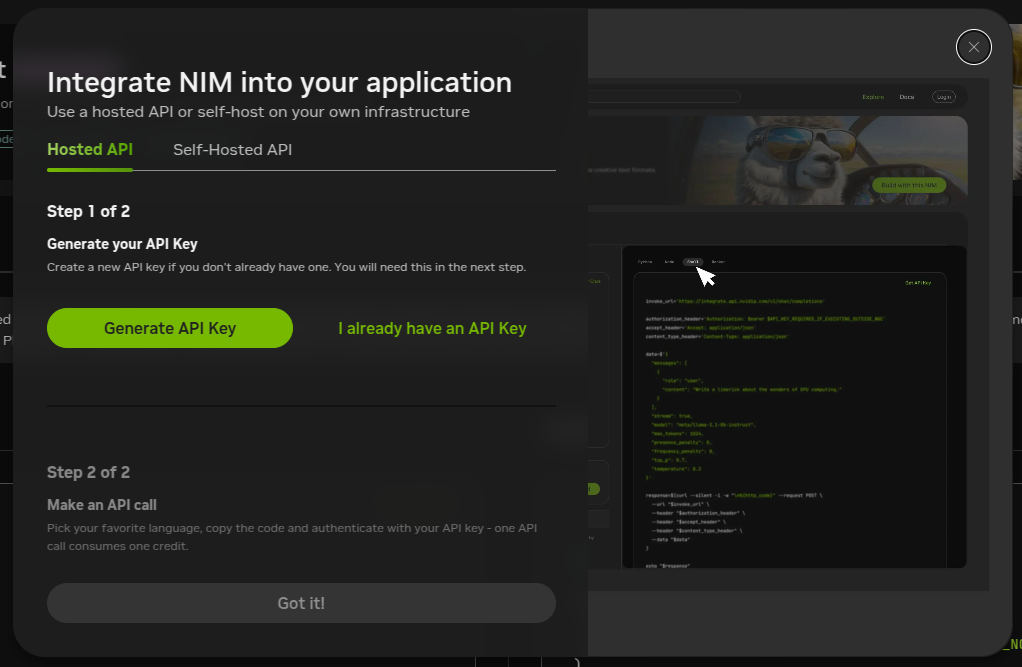
Ways to use this model(using the NIM):
-
Hosted API: Using NVIDIA Inference Microservices(NIM) with Nvidia’s infrastructure access the model. (But in this you can only use 1000 api calls per month)
-
Self-hosted API: Using NVIDIA Inference Microservices(NIM) with your own infrastructure access the model. And in this case you can use infinite api calls to use the model.
nvidia/nv-embedqa-e5-v5
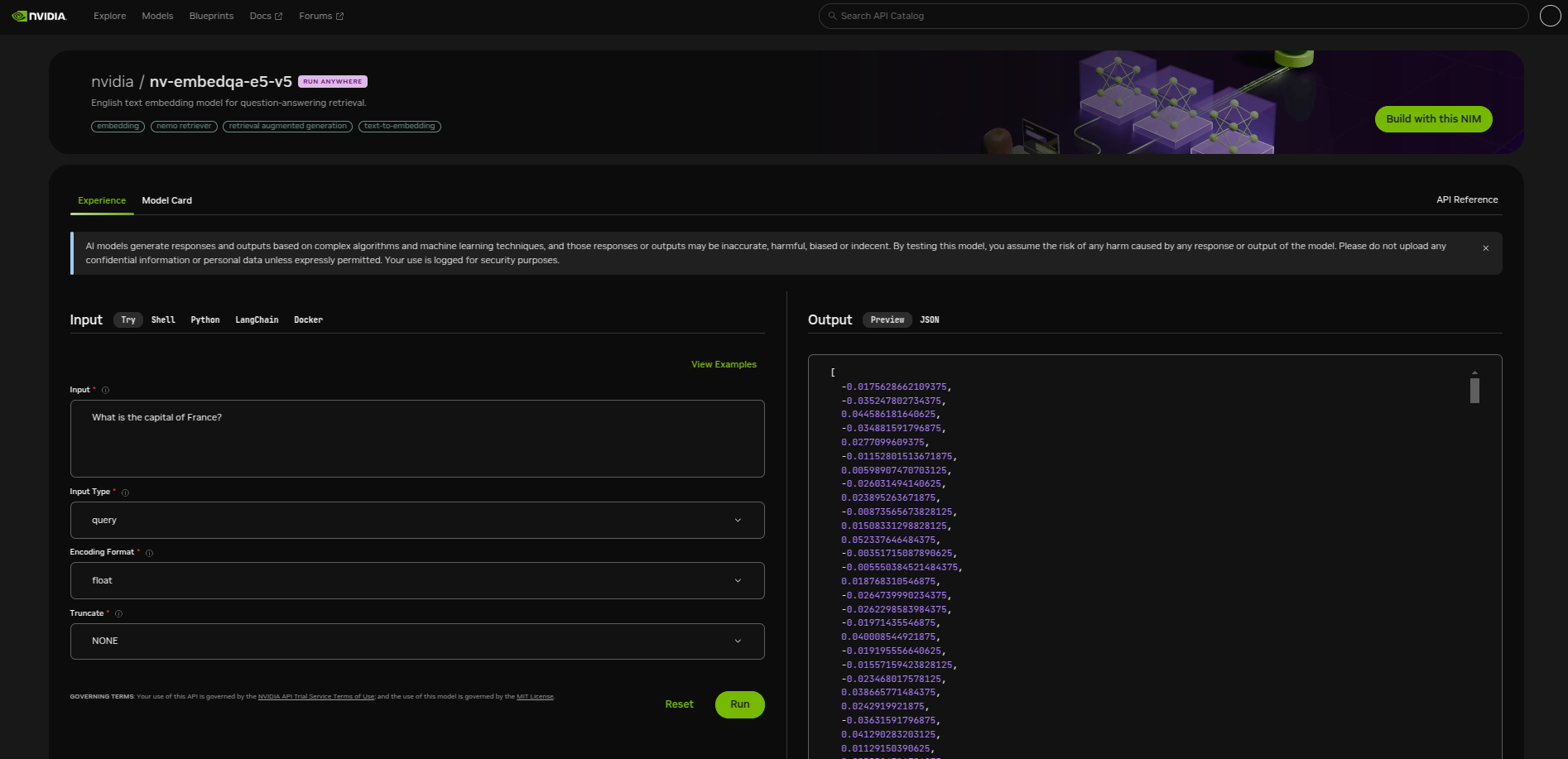
The NVIDIA Retrieval QA E5 Embedding Model is an embedding model optimized for text question-answering retrieval.
Ways to use this model(using the NIM):
Same as previous model.
Popular Model Categories
1. Large Language Models (LLMs)
NVIDIA offers several state-of-the-art LLMs optimized for different use cases:
Llama 2
- Variants: 7B, 13B, and 70B parameters
- Use Cases: Text generation, summarization, translation
- Features:
- Open-source architecture
- Fine-tuning capabilities
- Optimized for enterprise deployment
Mistral
- Variants: 7B base and instruct models
- Key Strengths:
- Exceptional performance despite smaller size
- Enhanced context handling
- Efficient inference speed
GPT-3 Compatible Models
- Multiple parameter sizes available
- Optimized for enterprise applications
- Support for custom fine-tuning
2. Computer Vision Models
Detection Models
- YOLO Family:
- YOLOv8
- YOLOv5
- Features real-time object detection
- Multiple backbone options
Classification Models
- ResNet Family:
- ResNet50
- ResNet101
- ResNet152
- EfficientNet Series
- Vision Transformers (ViT)
Segmentation Models
- Mask R-CNN
- DeepLab v3
- Segment Anything Model (SAM)
3. Speech AI Models
Speech Recognition
- Riva ASR:
- Support for 50+ languages
- Real-time transcription
- Custom vocabulary support
Text-to-Speech
- Riva TTS:
- Multiple voices and languages
- Emotional synthesis
- Custom voice adaptation
4. Multimodal Models
Text-to-Image
- Stable Diffusion:
- Multiple versions (1.5, 2.1, XL)
- LoRA support
- Custom pipeline integration
Image-to-Text
- BLIP-2
- GIT-large
Deployment Options
1. Cloud Deployment
- NVIDIA Cloud Services:
- Managed infrastructure
- Automatic updates
- Pay-as-you-go pricing
- Major Cloud Providers:
- AWS
- Google Cloud
- Azure
2. On-Premises Deployment
- Requirements:
- NVIDIA-Certified Systems
- NVIDIA AI Enterprise software
- Container runtime environment
3. Hybrid Deployment
- Flexible architecture
- Load balancing across environments
- Disaster recovery options
Performance Optimization
1. TensorRT Integration
- Automatic optimization
- Reduced inference latency
- Lower memory footprint
- Support for multiple precision types:
- FP32
- FP16
- INT8
2. Triton Inference Server
- Dynamic batching
- Model ensemble support
- Multiple framework support:
- TensorRT
- ONNX Runtime
- PyTorch
- TensorFlow
Industry-Specific Solutions
1. Healthcare
- Medical imaging analysis
- Diagnostic assistance
- Patient data processing
- Drug discovery acceleration
2. Financial Services
- Fraud detection
- Risk assessment
- Trading algorithms
- Document processing
3. Manufacturing
- Quality control
- Predictive maintenance
- Process optimization
- Visual inspection
4. Retail
- Inventory management
- Customer behavior analysis
- Recommendation systems
- Visual search
Best Practices for Implementation
1. Model Selection
- Consider use case requirements
- Evaluate performance metrics
- Assess resource requirements
- Review licensing terms
2. Infrastructure Planning
- GPU selection and sizing
- Network architecture
- Storage requirements
- Scaling strategy
3. Monitoring and Maintenance
- Performance metrics tracking
- Resource utilization
- Model accuracy monitoring
- Regular updates and patches
Security Considerations
1. Model Security
- Access control
- Encryption at rest and in transit
- Secure model updates
- Audit logging
2. Data Privacy
- GDPR compliance
- Data encryption
- Access controls
- Privacy-preserving inference
3. Infrastructure Security
- Network security
- Container security
- Authentication and authorization
- Vulnerability management
Cost Optimization
1. Resource Planning
- Right-sizing infrastructure
- Batch processing optimization
- Auto-scaling configuration
- Storage optimization
2. Deployment Strategies
- Multi-tenant architecture
- Load balancing
- Caching mechanisms
- Resource scheduling
Future Developments
NVIDIA continues to expand its NIM offerings with:
- New Model Architectures
- Mixture of Experts (MoE) models
- Efficient attention mechanisms
- Specialized domain models
- Enhanced Optimization
- Improved quantization techniques
- Advanced pruning methods
- Better resource utilization
- Extended Platform Support
- New hardware architectures
- Additional cloud providers
- Enhanced deployment options
Conclusion
NVIDIA Inference Microservices represent a comprehensive solution for deploying AI models in production environments. With its extensive model catalog, optimization tools, and deployment options, NIM provides organizations with the flexibility and scalability needed for modern AI applications. As the field continues to evolve, NVIDIA’s commitment to expanding and improving its offerings ensures that organizations can stay at the forefront of AI technology while maintaining efficient and cost-effective operations.
For more information and access to the latest models, visit the NVIDIA Models catalog and explore the documentation for specific implementation details and best practices.